GPT를 제대로 활용하기 위해 파인튜닝 하는 과정을 거쳐야하는데요, 오늘은 xlsx, csv 파일을 업로드해서 GPT 파인튜닝 하는 법을 알아보도록 하겠습니다. 하기 전에 API 발급은 필수이므로 API 발급 받는 법은 아래 링크에서 확인해주세요.
[GPT] GPT API 키 발급 받기, 리미트 지정하는 방법
GPT의 API를 발급 받고 결제 제한 지정하는 방법에 대해서 알아보겠습니다. 1. openai 접속 gpt로 접속하는게 아니라 openai 홈페이지로 접속해야 합니다. https://openai.com/ OpenAI Creating safe AGI that benefits al
combee.tistory.com
진행할 순서는 아래와 같습니다.

1. open ai 라이브러리 설치
pip install openai로 라이브러리를 설치해줍니다.
2. 코드 입력
필요한 라이브러리 불러와주고 발급받은 api key 입력해줍니다. 아래의 본인 api key 입력해주세요. 부분에 입력하시면 됩니다.
import json
import openai
import os
import pandas as pd
from pprint import pprint
# api key 입력
client = openai.OpenAI(api_key=os.environ.get("OPENAI_API_KEY", "본인 API Key 입력해주세요."))저는 csv 파일 데이터를 업로드해서 학습시킬 것이기 때문에, 파일 불러와줍니다.
# raw
iphone_df = pd.read_csv("C:/Users/Desktop/iphone.csv", encoding = "utf-8-sig")이제부터 프롬프트를 입력해줄건데요. 먼저 프롬프트 구성에 대해 알아야해서 설명해드리겠습니다.
GPT 관련 공식 문서에서 가져온 자료인데요. 아래에 보면 크게 역할(role)이 system, user, assistant로 나눠져있고, 각 역할의 내용은 아래와 같습니다.
- system: 시스템의 역할에 대한 정의. "너는 무엇을 해주는 어시스턴트다." "너는 키워드를 추출하는 모델이야." 처럼 목적을 정의해준다
- user: 사용자(나)가 입력하는 질문
- assistant: user에 대한 답

이렇게 system, user, assistant에 대한 데이터를 준비해서 학습데이터로 던져줘야 모델이 잘 학습할 수 있습니다.
그래서 아래의 코드를 보면 저는 system_message에 "너는 아이폰 고장 키워드를 추출해주는 도우미야. ..." 처럼 입력했습니다. 제가 업로드한 csv 파일에는 user에 해당하는 질문 데이터와, assistant에 해당하는 답변 데이터가 들어있습니다.
기본적인 프롬프트 구성에 대한 설명은 끝났고 아래의 코드를 수정해서 입력해주시면 됩니다.
# 프롬프트 구성
training_data = []
system_message = "You are an assistant who extracts breakdowns for iphones. Please keyword extract which breakdowns are in each data."
def create_user_message(row):
return f"""Title: {row['title']}\n\summary: {row['summary']}\n\nGeneric ingredients: """
def prepare_example_conversation(row):
messages = []
messages.append({"role": "system", "content": system_message})
user_message = create_user_message(row)
messages.append({"role": "user", "content": user_message})
messages.append({"role": "assistant", "content": row["breakdown"]})
return {"messages": messages}
pprint(prepare_example_conversation(iphone_df.iloc[0]))다음은 학습 데이터를 생성, 저장, 업로드 하는 과정입니다. 주석 모두 붙여뒀으니 어렵지 않게 이해하실 수 있을겁니다. 정상적으로 코드를 돌렸다면 training file id가 출력될겁니다.
# 학습 데이터 생성
# use the first n rows of the dataset for training
training_df = iphone_df.loc[0:39]
# apply the prepare_example_conversation function to each row of the training_df
training_data = training_df.apply(prepare_example_conversation, axis=1).tolist()
# 학습 데이터를 파일로 저장
def write_jsonl(data_list: list, filename: str) -> None:
with open(filename, "w") as out:
for ddict in data_list:
jout = json.dumps(ddict) + "\n"
out.write(jout)
training_file_name = "iphone_finetune_training.jsonl"
write_jsonl(training_data, training_file_name)
# 학습 데이터 업로드
with open(training_file_name, "rb") as training_fd:
training_response = client.files.create(
file=training_fd, purpose="fine-tune"
)
training_file_id = training_response.id
print("Training file ID:", training_file_id)이제 파인 튜닝을 실행하는 코드를 작성해줍니다. 저는 테스트용으로 데이터를 40건 정도밖에 안 넣었는데도 시간이 좀 걸리네요. 혹시 저보다 큰 용량 넣으셨으면 한참 걸리실 것으로 보입니다.
# 파인 튜닝 실행
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
model="gpt-3.5-turbo",
suffix="iphone-ner",
)
job_id = response.id
print("Job ID:", response.id)
print("Status:", response.status)걸리시는 동안 작업상태(진행 중, 완료)를 확인하고 싶으시면 아래의 코드를 입력해보시거나, GPT API 홈페이지로 이동하셔서 확인하실 수 있습니다.
# 작업 상태 확인
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
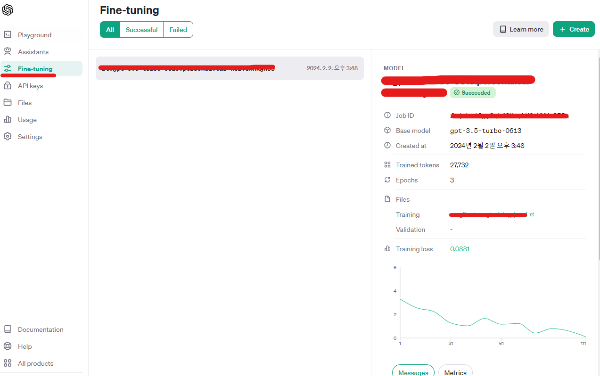
print("Trained Tokens:", response.trained_tokens)파인 튜닝 작업이 완료되면 아래와 같이 succeeded로 나옵니다.

3. 결과 확인 및 비용
구체적 결과 확인은 GPT API 홈페이지에서 할 수 있습니다. 홈에서 파인튜닝 메뉴로 가면 파인튜닝 정보가 나타납니다. 그래프 밑으로 스크롤을 내려보면 시간도 나오는데 저는 40건의 데이터를 학습시키는데 7분 정도가 소요되었네요.
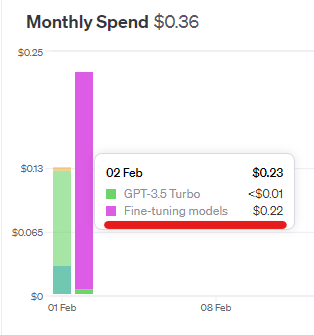
비용은 Usage 메뉴에서 확인할 수 있습니다. 저 같은 경우는 40건의 데이터를 학습시키는데 0.22달러가 들었습니다.
생성한 파인튜닝 모델을 사용하는 방법은 아래에서 확인해주세요.
[GPT] 파인튜닝 모델로 엑셀 결과물 생성하기
이전 글에 GPT 파인 튜닝 하는 방법을 작성했었습니다. 이번에는 파인 튜닝한 모델을 불러와서 데이터에 적용하고, 엑셀 결과물을 만들어내는 방법을 알아보겠습니다. [GPT] 파인튜닝(Fine tuning) 하
combee.tistory.com
함께 보면 좋은 글) 옵시디언, GPT로 AI 메모하기
[옵시디언] 메모에 AI(GPT)를 적용해보자 smart connections
저는 옵시디언을 이용해서 주로 메모 및 정리를 하는데요. 옵시디언에 smart connections라는 플러그인이 있어서 한 번 사용해보고, 사용방법도 정리해보도록 하겠습니다. 1. 설치 방법 커뮤니티 플
combee.tistory.com
'테크' 카테고리의 다른 글
| OpenAI, 샘 올트먼이 꿈꾸는 AGI (0) | 2024.02.13 |
|---|---|
| [GPT] 파인튜닝 모델로 엑셀 결과물 생성하기 (1) | 2024.02.07 |
| [바드] 무료 이미지 생성 AI로 활용하기 (1) | 2024.02.05 |
| 갤럭시링 출시일, 디자인, 가격, 기능 알아보기 (0) | 2024.02.03 |
| [GPT] GPT API 키 발급 받기, 리미트 지정하는 방법 (0) | 2024.02.01 |